SuperCLUE年榜出炉 海外闭源领跑,国产在单项任务“抢第一”

SuperCLUE近日发布的《2025年度中文大模型基准测评报告》显示,本次共有23个国内外大模型参与,覆盖数学推理、科学推理、代码生成等六大维度。该报告同时给出综合评分与分项成绩,用于对比不同模型在中文场景下的能力结构。
(图片来源:SuperCLUE)
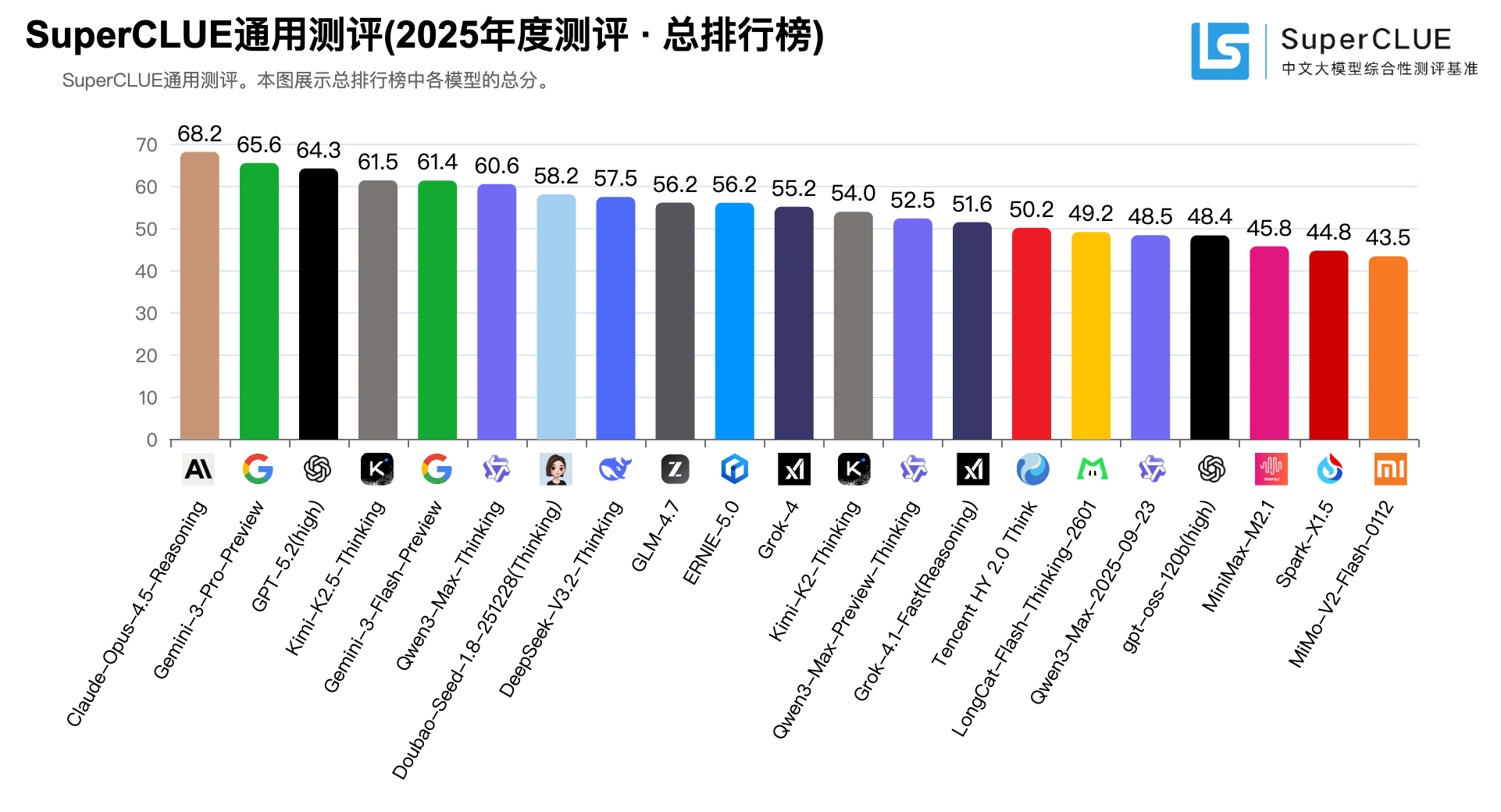
在综合榜单上,海外闭源模型仍稳居第一梯队。Anthropic 的 Claude-Opus-4.5-Reasoning 以 68.25分排名第一,Google 的 Gemini-3-Pro-Preview 以 65.59分位列第二,OpenAI 的 GPT-5.2(high) 以 64.32分排在第三。
 (图片来源:SuperCLUE)
(图片来源:SuperCLUE)
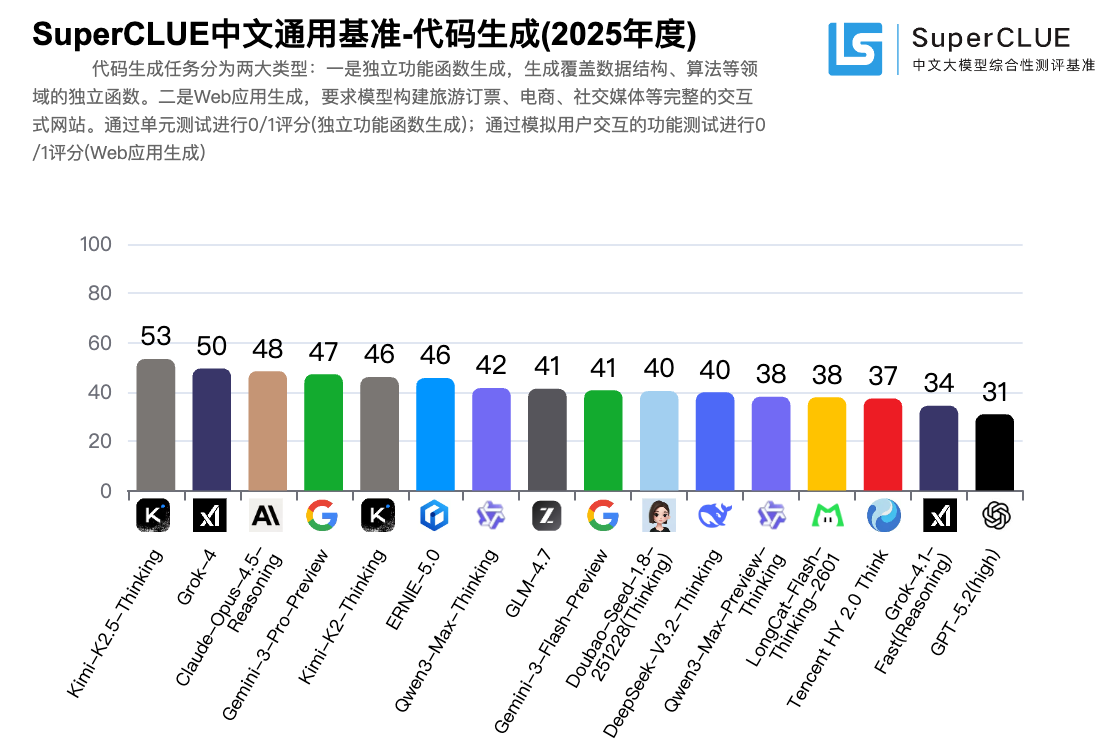
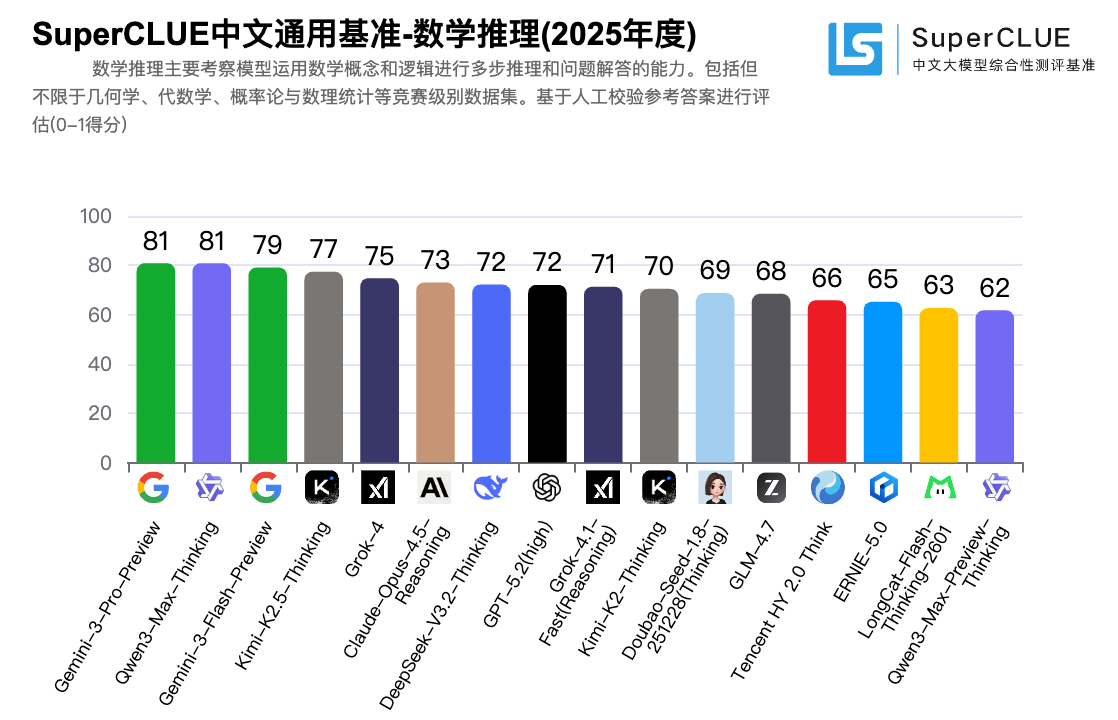
更吸引讨论的部分来自“分项冠军”。转述信息显示,开源模型 Kimi-K2.5-Thinking 在代码生成任务以 53.33分拿到第一;闭源模型 Qwen3-Max-Thinking 在数学推理任务与 Gemini-3-Pro-Preview 并列第一,成绩为 80.87分。
(图片来源:SuperCLUE)
在综合名次上,国产模型同样出现了更靠前的站位。媒体转述称,Kimi-K2.5-Thinking 综合得分 61.50分排名第四,Qwen3-Max-Thinking 综合得分 60.61分进入前列(第六名)。这些数字意味着“追分”不再只体现在总分差距缩小,而是开始落在更具体的任务表现上。
从榜单呈现出来的结构看:综合能力上,海外闭源仍有明显优势;但在更贴近落地的分项任务里,国产模型已经能在高频场景里拿到单项第一或并列第一。国产开源在Top序列的存在感更强,形成了“综合强者仍在,但开源追赶更凶”的对照。
这类测评的价值,往往体现在“给选型提供线索”。很多团队并不会只按“总分最高”来决定用谁,而是先看自己的刚需:写代码、做数学推理、做结构化分析、做特定工具链集成,再去比对对应能力是否稳定。分项冠军出现国产模型名字,至少意味着它们更可能进入同一张评估表。
SuperCLUE方面也在官方介绍中强调,其目标是为中文通用大模型提供可对比的测评基准,并持续更新榜单与任务体系。其页面也提到评测体系包含OPEN多轮开放式、OPT客观题等组成,用于从不同角度刻画模型能力。对外界而言,这意味着榜单更适合作为“能力雷达”,而非一次性定论。
这份年榜放到更长的时间轴上,它释放的信号也更偏“趋势”:海外闭源仍守住综合优势,国产模型则在代码、数学推理等硬任务上把差距压到更可见的范围。接下来更关键的,将是这些分项优势能否沉淀为稳定的工程体验、可控的成本与持续的生态供给。
Source:SuperCLUE cluebenchmarks.com
编辑:Vivian







