DeepSeek V4发布前夜,罗福莉亮剑!小米最强模型MiMo-V2.5深夜突袭

4月23日凌晨,小米MiMo大模型一口气官宣4款新模型:旗舰推理模型MiMo-V2.5、全模态Agent模型V2.5-Pro开启公测并即将开源,V2.5-TTS Series和V2.5-ASR即将推出。
带领小米大模型团队的,正是原DeepSeek核心成员、被誉为“天才少女”的罗福莉。这距离上一代MiMo-V2系列发布仅过去36天。极短的产品周期背后,是小米正在赌一个更大的未来。

最强模型现身:4.3小时“徒手”搓出编译器
MiMo-V2.5-Pro是本次发布中最重磅的产品。据官方信息,该模型在通用智能体能力、复杂软件工程等维度上,已能与Claude Opus 4.6、GPT-5.4等全球顶尖Agent模型正面抗衡。
小米公布了一项令行业侧目的实测案例:在开发北京大学《编译原理》课程中的SysY编译器项目时,原本需要本科生耗费数周的工作量,MiMo-V2.5-Pro仅用时4.3小时、通过672次工具调用便顺利完成,并在隐藏测试集取得满分233分。
在另一个复杂任务中,该模型独立构建了一个功能完整的Web视频编辑器,历时11.5小时、历经1868次工具调用。过程中,它甚至在执行至第512次重构时出现测试点回退,随后自行诊断、恢复并继续推进。这种在超长周期任务中保持逻辑一致性的能力,正在改变业界对大模型“理解浅、执行弱”的刻板印象。
降本才是杀手锏:省42% Token
性能对标是一回事,成本是另一回事。MiMo-V2.5系列真正令竞品紧张的地方,在于它用更少的Token实现了同等甚至更优的效果。
据官方披露,在智能体基准榜单ClawEval上取得相同分数的情况下,MiMo-V2.5-Pro相比Kimi本周发布的Kimi K2.6节省了42% Token;MiMo-V2.5相比Meta本月初发布的Muse Spark节省了50% Token。
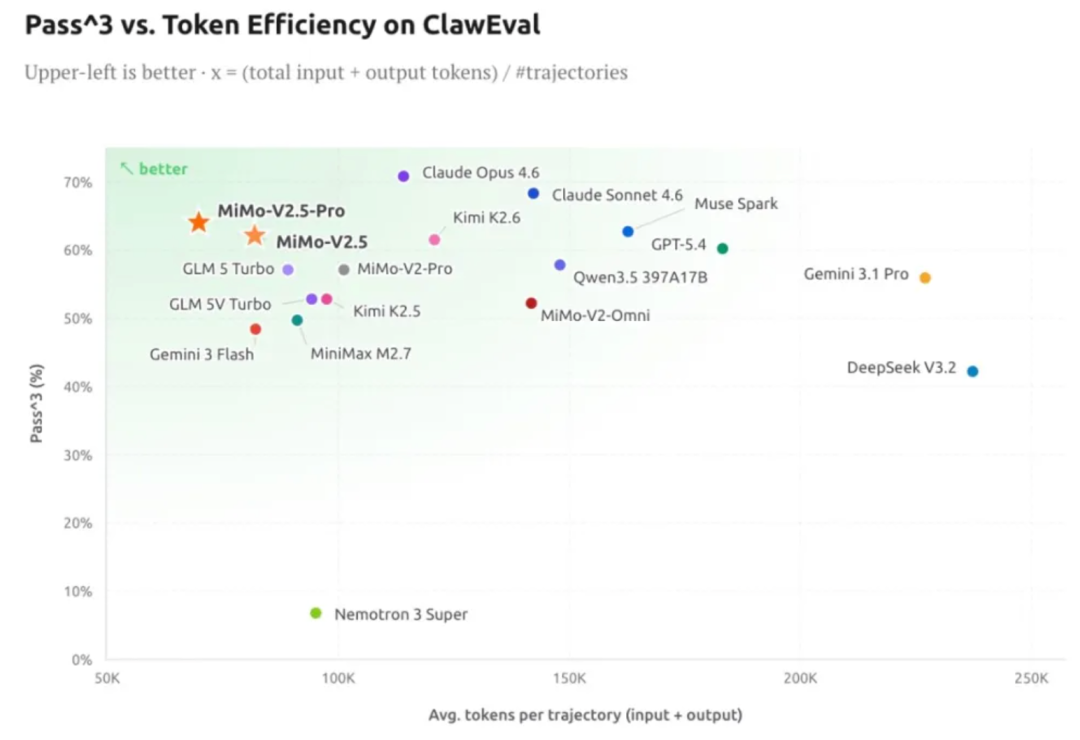
在保证推理质量的前提下把Token成本压下来,是模型走向规模商业化的关键前提。V2.5系列相比上一代V2-Pro,API成本降低了约50%。同步优化的还有Token Plan订阅体系,一系列降本动作直指企业用户的算力成本痛点。
抢在DeepSeek V4之前:罗福莉的亮剑时机
一个不容忽视的时间点:DeepSeek创始人梁文锋此前已透露,新一代旗舰大模型DeepSeek V4将于4月下旬正式发布。
而罗福莉正是从DeepSeek走出来的核心成员。她在前东家新一代旗舰发布前夕带队抢跑,这一微妙的时间线让此次发布平添了几分火药味——不是简单的产品迭代,而是一封来自竞争对手的“宣战书”。
36天前,罗福莉率领的小米大模型团队还被视为国产AI赛道上的追赶者。36天后,MiMo-V2.5系列正在改写这个叙事。当DeepSeek V4即将面世,当OpenAI、Anthropic仍在持续升级,这场AI竞赛的下一轮高潮,才刚刚拉开帷幕。
编辑:Vivian







