MiniMax 发布 M2.5:一小时1美金的Agent时代

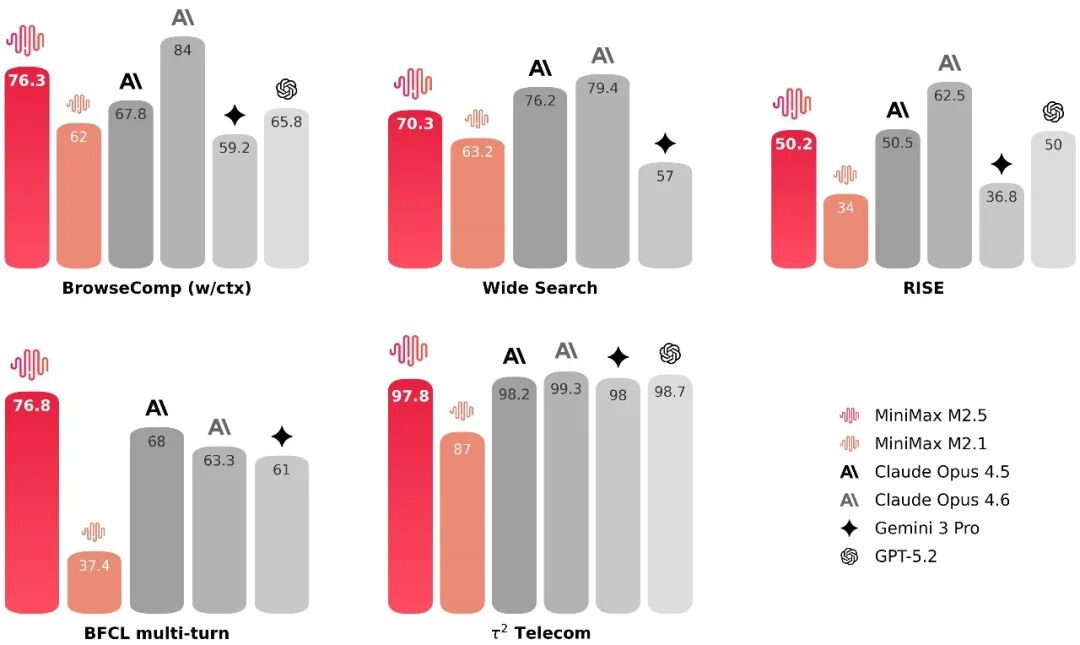
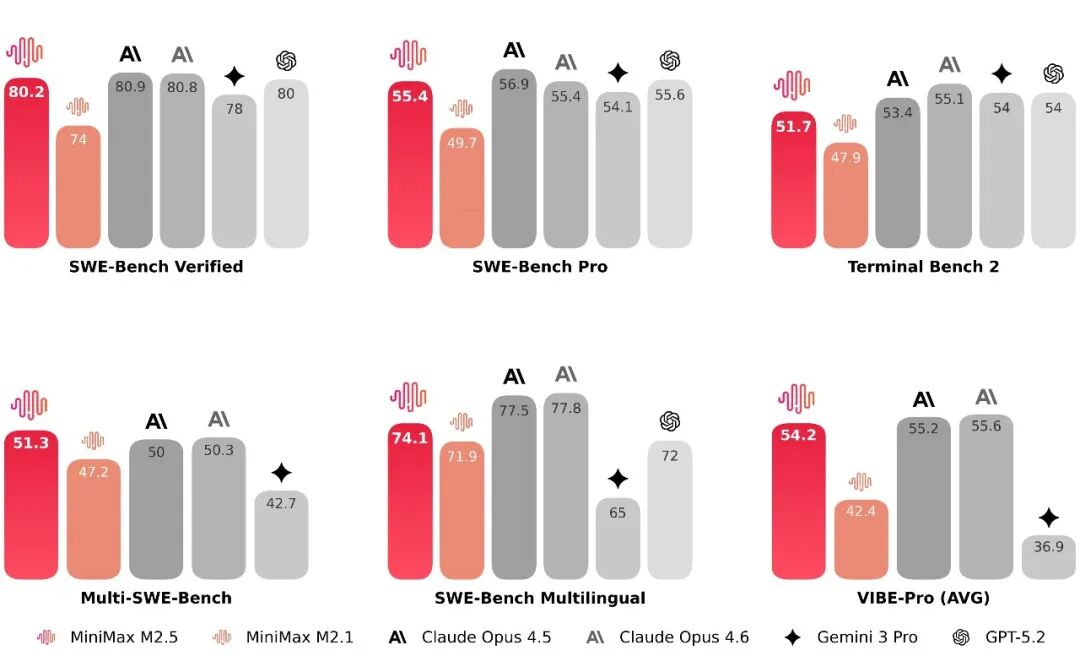
M2.5 是 M2 系列的最新迭代版本。官方数据显示,其在 SWE-Bench Verified 上达到 80.2%,在 Multi-SWE-Bench 上为 51.3%,BrowseComp 为 76.3%,多项生产力场景测试达到或刷新行业 SOTA。
(图片来源:MiniMax)
与上一代 M2.1 相比,M2.5 在复杂任务拆解能力与 token 效率上显著优化。在 SWE-Bench Verified 测试中,端到端任务平均耗时从 31.3 分钟缩短至 22.8 分钟,速度提升 37%,同时单任务 token 消耗从 3.72M 降至 3.52M。
(图片来源:MiniMax)
在编程能力上,M2.5 被定位为“像架构师一样思考和构建”。模型在超过 10 种语言及数十万个真实环境中训练,覆盖从 0-1 系统设计、环境构建,到功能迭代、代码评审与系统测试的完整流程,而非仅生成演示级代码。
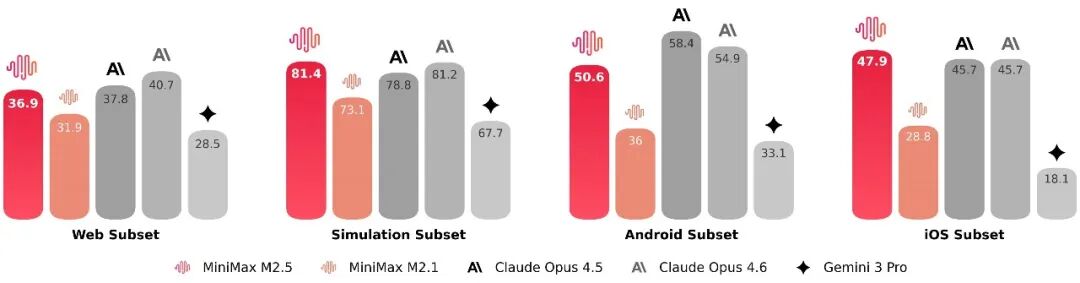
在不同脚手架环境测试中,M2.5 的泛化能力也有所提升。在 Droid 上通过率为 79.7%,高于 M2.1 的 71.3 和 Opus 4.6 的 78.9;在 OpenCode 上为 76.1%,同样领先前代模型。官方还升级了 VIBE 基准至 Pro 版本,提高任务复杂度与评估精度,M2.5 与主流顶级模型表现接近。
(图片来源:MiniMax)
搜索与工具调用能力是 Agent 自动化执行的关键。M2.5 在 BrowseComp、Wide Search 等评测中进入行业顶尖,并在内部构建的 RISE(Realistic Interactive Search Evaluation)真实专家级搜索测试中取得领先表现。相较 M2.1,在多项搜索任务中节省约 20% 轮次消耗,体现出更成熟的决策路径与 token 利用率。
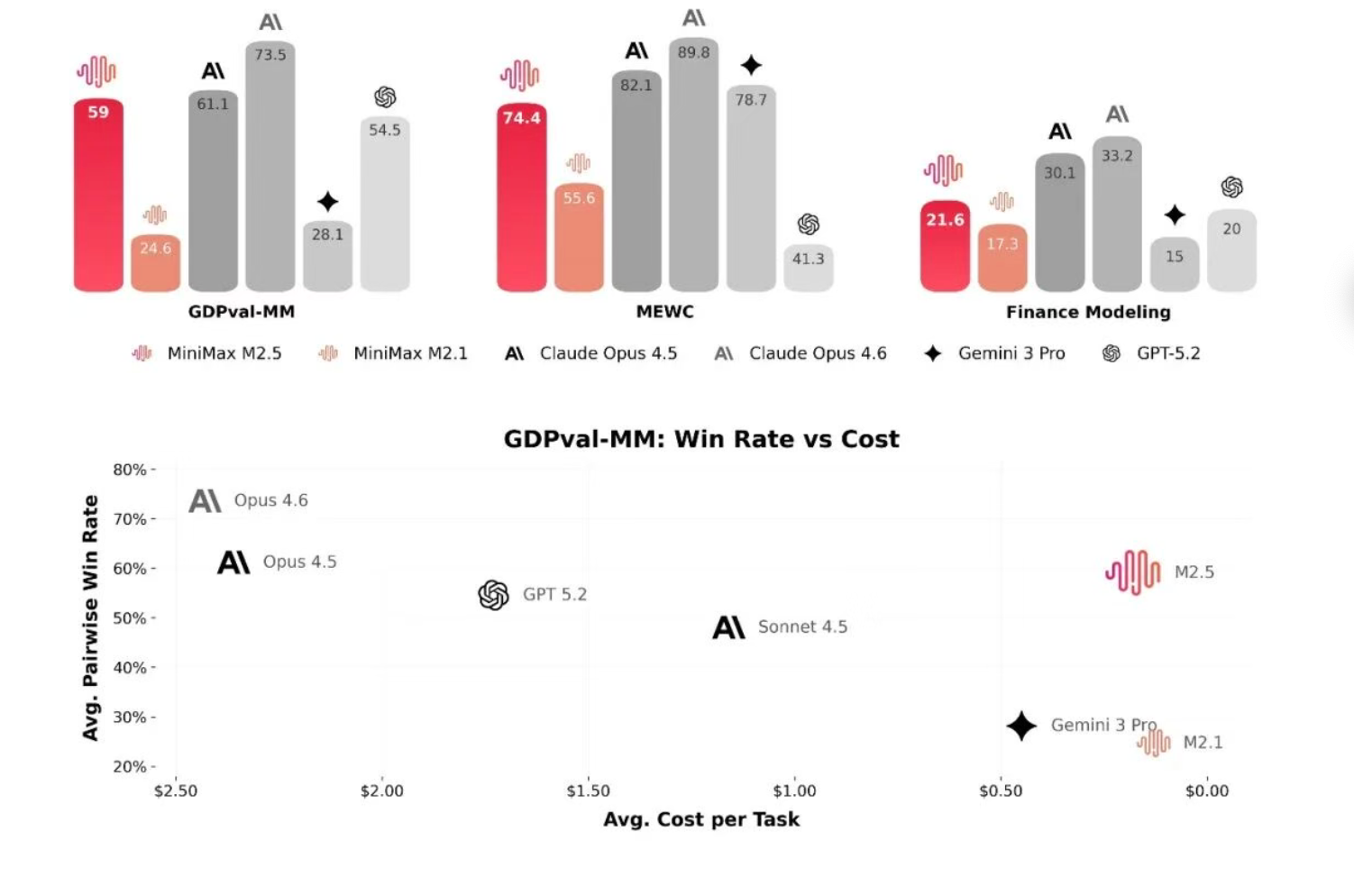
在办公场景,MiniMax 与金融、法律、社会科学从业者合作,将行业隐性知识结构化纳入训练流程。M2.5 在 Word、PPT、Excel 金融建模等高阶任务中能力提升显著。在内部 Cowork Agent 评测框架(GDPval-MM)中,与主流模型对比取得 59.0% 的平均胜率。
(图片来源:MiniMax)
成本模型是 M2.5 另一核心亮点。官方提供 100 TPS 与 50 TPS 两个版本,前者每百万 token 输入价格 0.3 美元,输出 2.4 美元;50 TPS 版本输出价格再减半。按照 100 token/秒输出计算,连续运行一小时成本约 1 美元,50 token/秒时仅 0.3 美元。以此推算,1 万美元可支持 4 个 Agent 连续运行一年。
MiniMax 表示,其内部真实业务中已有 30% 任务由 M2.5 自主完成,覆盖研发、产品、销售、HR、财务等职能。在编程场景中,M2.5 生成代码已占新提交代码的 80%。
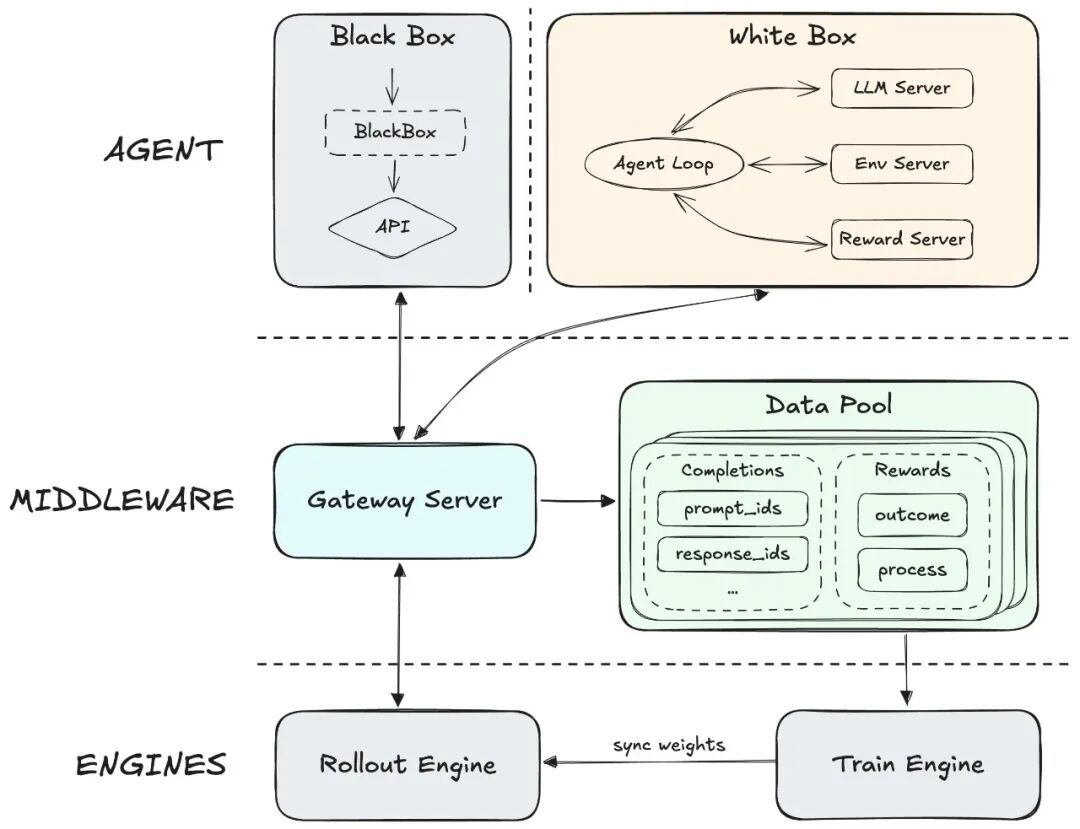
支撑这一迭代速度的,是大规模强化学习与原生 Agent RL 框架 Forge。该框架通过中间层解耦训练与 Agent 环境,支持任意脚手架接入,并通过异步调度与树状样本合并策略实现约 40 倍训练加速。结合 CISPO 算法与过程奖励机制,模型在长上下文 Agent 场景下保持稳定性与信用分配能力。
(图片来源:MiniMax)
过去 108 天内,MiniMax 连续发布 M2、M2.1、M2.5,多项核心指标持续攀升。官方强调,其目标是“在没有成本约束的情况下运行复杂 Agent”,而 M2.5 已接近这一阶段。
随着 M2.5 在 MiniMax Agent、API 及订阅产品全面上线,并计划在 HuggingFace 开源模型权重支持本地部署,模型能力、推理速度与经济性三条曲线正在汇合。对于 Agent 应用而言,门槛不再只是能力,而是如何把这种能力嵌入真实工作流。(Source:MiniMax)
编辑:Vivian








